Summary:
The patch does some cleanup in and around `VersionStorageInfo`:
* Renames the method `PrepareApply` to `PrepareAppend` in `Version`
to make it clear that it is to be called before appending the `Version` to
`VersionSet` (via `AppendVersion`), not before applying any `VersionEdit`s.
* Introduces a helper method `VersionStorageInfo::PrepareForVersionAppend`
(called by `Version::PrepareAppend`) that encapsulates the population of the
various derived data structures in `VersionStorageInfo`, and turns the
methods computing the derived structures (`UpdateNumNonEmptyLevels`,
`CalculateBaseBytes` etc.) into private helpers.
* Changes `Version::PrepareAppend` so it only calls `UpdateAccumulatedStats`
if the `update_stats` flag is set. (Earlier, this was checked by the callee.)
Related to this, it also moves the call to `ComputeCompensatedSizes` to
`VersionStorageInfo::PrepareForVersionAppend`.
* Updates and cleans up `version_builder_test`, `version_set_test`, and
`compaction_picker_test` so `PrepareForVersionAppend` is called anytime
a new `VersionStorageInfo` is set up or saved. This cleanup also involves
splitting `VersionStorageInfoTest.MaxBytesForLevelDynamic`
into multiple smaller test cases.
* Fixes up a bunch of comments that were outdated or just plain incorrect.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9494
Test Plan: Ran `make check` and the crash test script for a while.
Reviewed By: riversand963
Differential Revision: D33971666
Pulled By: ltamasi
fbshipit-source-id: fda52faac7783041126e4f8dec0fe01bdcadf65a
Summary:
Fixes a major performance regression in 6.26, where
extra CPU is spent in SliceTransform::AsString when reads involve
a prefix_extractor (Get, MultiGet, Seek). Common case performance
is now better than 6.25.
This change creates a "fast path" for verifying that the current prefix
extractor is unchanged and compatible with what was used to
generate a table file. This fast path detects the common case by
pointer comparison on the current prefix_extractor and a "known
good" prefix extractor (if applicable) that is saved at the time the
table reader is opened. The "known good" prefix extractor is saved
as another shared_ptr copy (in an existing field, however) to ensure
the pointer is not recycled.
When the prefix_extractor has changed to a different instance but
same compatible configuration (rare, odd), performance is still a
regression compared to 6.25, but this is likely acceptable because
of the oddity of such a case. The performance of incompatible
prefix_extractor is essentially unchanged.
Also fixed a minor case (ForwardIterator) where a prefix_extractor
could be used via a raw pointer after being freed as a shared_ptr,
if replaced via SetOptions.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9407
Test Plan:
## Performance
Populate DB with `TEST_TMPDIR=/dev/shm/rocksdb ./db_bench -benchmarks=fillrandom -num=10000000 -disable_wal=1 -write_buffer_size=10000000 -bloom_bits=16 -compaction_style=2 -fifo_compaction_max_table_files_size_mb=10000 -fifo_compaction_allow_compaction=0 -prefix_size=12`
Running head-to-head comparisons simultaneously with `TEST_TMPDIR=/dev/shm/rocksdb ./db_bench -use_existing_db -readonly -benchmarks=seekrandom -num=10000000 -duration=20 -disable_wal=1 -bloom_bits=16 -compaction_style=2 -fifo_compaction_max_table_files_size_mb=10000 -fifo_compaction_allow_compaction=0 -prefix_size=12`
Below each is compared by ops/sec vs. baseline which is version 6.25 (multiple baseline runs because of variable machine load)
v6.26: 4833 vs. 6698 (<- major regression!)
v6.27: 4737 vs. 6397 (still)
New: 6704 vs. 6461 (better than baseline in common case)
Disabled fastpath: 4843 vs. 6389 (e.g. if prefix extractor instance changes but is still compatible)
Changed prefix size (no usable filter) in new: 787 vs. 5927
Changed prefix size (no usable filter) in new & baseline: 773 vs. 784
Reviewed By: mrambacher
Differential Revision: D33677812
Pulled By: pdillinger
fbshipit-source-id: 571d9711c461fb97f957378a061b7e7dbc4d6a76
Summary:
The LastSequence field in the MANIFEST file is the baseline seqno for a recovered DB. Recovering WAL entries might cause the recovered DB's seqno to advance above this baseline, but the recovered DB will never use a smaller seqno.
Before this PR, we were writing the DB's seqno at the time of LogAndApply() as the LastSequence value. This works in the sense that it is a large enough baseline for the recovered DB that it'll never overwrite any records in existing SST files. At the same time, it's arbitrarily larger than what's needed. This behavior comes from LevelDB, where there was no tracking of largest seqno in an SST file.
Now we know the largest seqno of newly written SST files, so we can write an exact value in LastSequence that actually reflects the largest seqno in any file referred to by the MANIFEST. This is primarily useful for correctness testing with unsynced data loss, where the recovered DB's seqno needs to indicate what records were recovered.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9305
Test Plan:
- https://github.com/facebook/rocksdb/issues/9338 adds crash-recovery correctness testing coverage for WAL disabled use cases
- https://github.com/facebook/rocksdb/issues/9357 will extend that testing to cover file ingestion
- Added assertion at end of LogAndApply() for `VersionSet::descriptor_last_sequence_` consistency with files
- Manually tested upgrade/downgrade compatibility with a custom crash test that randomly picks between a `db_stress` built with and without this PR (for old code it must run with `-disable_wal=0`)
Reviewed By: riversand963
Differential Revision: D33182770
Pulled By: ajkr
fbshipit-source-id: 0bfafaf685f347cc8cb0e1d62e0186340a738f7d
Summary:
I'm working on a new format_version=6 to support context
checksum (https://github.com/facebook/rocksdb/issues/9058) and this includes much of the refactoring and test
updates to support that change.
Test coverage data and manual inspection agree on dead code in
block_based_table_reader.cc (removed).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9240
Test Plan:
tests enhanced to cover more cases etc.
Extreme case performance testing indicates small % regression in fillseq (w/ compaction), though CPU profile etc. doesn't suggest any explanation. There is enhanced correctness checking in Footer::DecodeFrom, but this should be negligible.
TEST_TMPDIR=/dev/shm/ ./db_bench -benchmarks=fillseq -memtablerep=vector -allow_concurrent_memtable_write=false -num=30000000 -checksum_type=1 --disable_wal={false,true}
(Each is ops/s averaged over 50 runs, run simultaneously with competing configuration for load fairness)
Before w/ wal: 454512
After w/ wal: 444820 (-2.1%)
Before w/o wal: 1004560
After w/o wal: 998897 (-0.6%)
Since this doesn't modify WAL code, one would expect real effects to be larger in w/o wal case.
This regression will be corrected in a follow-up PR.
Reviewed By: ajkr
Differential Revision: D32813769
Pulled By: pdillinger
fbshipit-source-id: 444a244eabf3825cd329b7d1b150cddce320862f
Summary:
Fix a bug that causes file temperature not preserved after DB is restarted, or options.max_manifest_file_size is hit.
Also, pass temperature information to NewRandomAccessFile() to allow users to hack a solution where they don't preserve tiering information.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9242
Test Plan: Add a unit test that would fail without the fix.
Reviewed By: jay-zhuang
Differential Revision: D32818150
fbshipit-source-id: 36aa3f148c60107f7b8e9d65b63b039f9e1a1eec
Summary:
The patch adds a new BlobDB configuration option `blob_compaction_readahead_size`
that can be used to enable prefetching data from blob files during compaction.
This is important when using storage with higher latencies like HDDs or remote filesystems.
If enabled, prefetching is used for all cases when blobs are read during compaction,
namely garbage collection, compaction filters (when the existing value has to be read from
a blob file), and `Merge` (when the value of the base `Put` is stored in a blob file).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9187
Test Plan: Ran `make check` and the stress/crash test.
Reviewed By: riversand963
Differential Revision: D32565512
Pulled By: ltamasi
fbshipit-source-id: 87be9cebc3aa01cc227bec6b5f64d827b8164f5d
Summary:
* Checksums are now checked on meta blocks unless specifically
suppressed or not applicable (e.g. plain table). (Was other way around.)
This means a number of cases that were not checking checksums now are,
including direct read TableProperties in Version::GetTableProperties
(fixed in meta_blocks ReadTableProperties), reading any block from
PersistentCache (fixed in BlockFetcher), read TableProperties in
SstFileDumper (ldb/sst_dump/BackupEngine) before table reader open,
maybe more.
* For that to work, I moved the global_seqno+TableProperties checksum
logic to the shared table/ code, because that is used by many utilies
such as SstFileDumper.
* Also for that to work, we have to know when we're dealing with a block
that has a checksum (trailer), so added that capability to Footer based
on magic number, and from there BlockFetcher.
* Knowledge of trailer presence has also fixed a problem where other
table formats were reading blocks including bytes for a non-existant
trailer--and awkwardly kind-of not using them, e.g. no shared code
checking checksums. (BlockFetcher compression type was populated
incorrectly.) Now we only read what is needed.
* Minimized code duplication and differing/incompatible/awkward
abstractions in meta_blocks.{cc,h} (e.g. SeekTo in metaindex block
without parsing block handle)
* Moved some meta block handling code from table_properties*.*
* Moved some code specific to block-based table from shared table/ code
to BlockBasedTable class. The checksum stuff means we can't completely
separate it, but things that don't need to be in shared table/ code
should not be.
* Use unique_ptr rather than raw ptr in more places. (Note: you can
std::move from unique_ptr to shared_ptr.)
Without enhancements to GetPropertiesOfAllTablesTest (see below),
net reduction of roughly 100 lines of code.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9163
Test Plan:
existing tests and
* Enhanced DBTablePropertiesTest.GetPropertiesOfAllTablesTest to verify that
checksums are now checked on direct read of table properties by TableCache
(new test would fail before this change)
* Also enhanced DBTablePropertiesTest.GetPropertiesOfAllTablesTest to test
putting table properties under old meta name
* Also generally enhanced that same test to actually test what it was
supposed to be testing already, by kicking things out of table cache when
we don't want them there.
Reviewed By: ajkr, mrambacher
Differential Revision: D32514757
Pulled By: pdillinger
fbshipit-source-id: 507964b9311d186ae8d1131182290cbd97a99fa9
Summary:
RocksDB does auto-readahead for iterators on noticing more than two sequential reads for a table file if user doesn't provide readahead_size. The readahead starts at 8KB and doubles on every additional read up to max_auto_readahead_size. However at each level, if iterator moves over next file, readahead_size starts again from 8KB.
This PR introduces a new ReadOption "adaptive_readahead" which when set true will maintain readahead_size at each level. So when iterator moves from one file to another, new file's readahead_size will continue from previous file's readahead_size instead of scratch. However if reads are not sequential it will fall back to 8KB (default) with no prefetching for that block.
1. If block is found in cache but it was eligible for prefetch (block wasn't in Rocksdb's prefetch buffer), readahead_size will decrease by 8KB.
2. It maintains readahead_size for L1 - Ln levels.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9056
Test Plan:
Added new unit tests
Ran db_bench for "readseq, seekrandom, seekrandomwhilewriting, readrandom" with --adaptive_readahead=true and there was no regression if new feature is enabled.
Reviewed By: anand1976
Differential Revision: D31773640
Pulled By: akankshamahajan15
fbshipit-source-id: 7332d16258b846ae5cea773009195a5af58f8f98
Summary:
Track per-SST user-defined timestamp information in MANIFEST https://github.com/facebook/rocksdb/issues/8957
Rockdb has supported user-defined timestamp feature. Application can specify a timestamp
when writing each k-v pair. When data flush from memory to disk file called SST files, file
creation activity will commit to MANIFEST. This commit is for tracking timestamp info in the
MANIFEST for each file. The changes involved are as follows:
1) Track max/min timestamp in FileMetaData, and fix invoved codes.
2) Add NewFileCustomTag::kMinTimestamp and NewFileCustomTag::kMinTimestamp in
NewFileCustomTag ( in the kNewFile4 part ), and support invoved codes such as
VersionEdit Encode and Decode etc.
3) Add unit test code for VersionEdit EncodeDecodeNewFile4, and fix invoved test codes.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9092
Reviewed By: ajkr, akankshamahajan15
Differential Revision: D32252323
Pulled By: riversand963
fbshipit-source-id: d2642898d6e3ad1fef0eb866b98045408bd4e162
Summary:
The patch refactors and unifies the logic in `VersionBuilder::SaveBlobFilesTo`
and `VersionBuilder::GetMinOldestBlobFileNumber` by introducing a generic
helper that can "merge" the list of `BlobFileMetaData` in the base version with
the list of `MutableBlobFileMetaData` representing the updated state after
applying a sequence of `VersionEdit`s. This serves as groundwork for subsequent
changes that will enable us to determine whether a blob file is live after applying
a sequence of edits without calling `VersionBuilder::SaveTo`.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9122
Test Plan: `make check`
Reviewed By: riversand963
Differential Revision: D32151472
Pulled By: ltamasi
fbshipit-source-id: 11622b475866de823334b8bc21b0e99d913af97e
Summary:
The patch refactors the parts of `VersionBuilder` that deal with SST file
comparisons. Specifically, it makes the following changes:
* Turns `NewestFirstBySeqNo` and `BySmallestKey` from free-standing
functions into function objects. Note: `BySmallestKey` has a pointer to the
`InternalKeyComparator`, while `NewestFirstBySeqNo` is completely
stateless.
* Eliminates the wrapper `FileComparator`, which was essentially an
unnecessary DIY virtual function call mechanism.
* Refactors `CheckConsistencyDetails` and `SaveSSTFilesTo` using helper
function templates that take comparator/checker function objects. Using
static polymorphism eliminates the need to make runtime decisions about
which comparator to use.
* Extends some error messages returned by the consistency checks and
makes them more uniform.
* Removes some incomplete/redundant consistency checks from `VersionBuilder`
and `FilePicker`.
* Improves const correctness in several places.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/9099
Test Plan: `make check`
Reviewed By: riversand963
Differential Revision: D32027503
Pulled By: ltamasi
fbshipit-source-id: 621326ae41f4f55f7ad6a91abbd6e666d5c7857c
Summary:
Right now, when options.ttl is set, compactions are triggered around the time when TTL is reached. This might cause extra compactions which are often bursty. This commit tries to mitigate it by picking those files earlier in normal compaction picking process. This is only implemented using kMinOverlappingRatio with Leveled compaction as it is the default value and it is more complicated to change other styles.
When a file is aged more than ttl/2, RocksDB starts to boost the compaction priority of files in normal compaction picking process, and hope by the time TTL is reached, very few extra compaction is needed.
In order for this to work, another change is made: during a compaction, if an output level file is older than ttl/2, cut output files based on original boundary (if it is not in the last level). This is to make sure that after an old file is moved to the next level, and new data is merged from the upper level, the new data falling into this range isn't reset with old timestamp. Without this change, in many cases, most files from one level will keep having old timestamp, even if they have newer data and we stuck in it.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8749
Test Plan: Add a unit test to test the boosting logic. Will add a unit test to test it end-to-end.
Reviewed By: jay-zhuang
Differential Revision: D30735261
fbshipit-source-id: 503c2d89250b22911eb99e72b379be154de3428e
Summary:
New classes FileStorageInfo and LiveFileStorageInfo and
'experimental' function DB::GetLiveFilesStorageInfo, which is intended
to largely replace several fragmented DB functions needed to create
checkpoints and backups.
This function is now used to create checkpoints and backups, because
it fixes many (probably not all) of the prior complexities of checkpoint
not having atomic access to DB metadata. This also ensures strong
functional test coverage of the new API. Specifically, much of the old
CheckpointImpl::CreateCustomCheckpoint has been migrated to and
updated in DBImpl::GetLiveFilesStorageInfo, with the former now
calling the latter.
Also, the class FileStorageInfo in metadata.h compatibly replaces
BackupFileInfo and serves as a new base class for SstFileMetaData.
Some old fields of SstFileMetaData are still provided (for now) but
deprecated.
Although FileStorageInfo::directory is accurate when using db_paths
and/or cf_paths, these have never been supported by Checkpoint
nor BackupEngine and still are not. This change does now detect
these cases and return NotSupported when appropriate. (More work
needed for support.)
Somehow this change broke ProgressCallbackDuringBackup, but
the progress_callback logic was dubious to begin with because it
would call the callback based on copy buffer size, not size actually
copied. Logic and test updated to track size actually copied
per-thread.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8968
Test Plan:
tests updated.
DB::GetLiveFilesStorageInfo mostly tested by use in CheckpointImpl.
DBTest.SnapshotFiles updated to also test GetLiveFilesStorageInfo,
including reading the data after DB close.
Added CheckpointTest.CheckpointWithDbPath (NotSupported).
Reviewed By: siying
Differential Revision: D31242045
Pulled By: pdillinger
fbshipit-source-id: b183d1ce9799e220daaefd6b3b5365d98de676c0
Summary:
The current BlobDB garbage collection logic works by relocating the valid
blobs from the oldest blob files as they are encountered during compaction,
and cleaning up blob files once they contain nothing but garbage. However,
with sufficiently skewed workloads, it is theoretically possible to end up in a
situation when few or no compactions get scheduled for the SST files that contain
references to the oldest blob files, which can lead to increased space amp due
to the lack of GC.
In order to efficiently handle such workloads, the patch adds a new BlobDB
configuration option called `blob_garbage_collection_force_threshold`,
which signals to BlobDB to schedule targeted compactions for the SST files
that keep alive the oldest batch of blob files if the overall ratio of garbage in
the given blob files meets the threshold *and* all the given blob files are
eligible for GC based on `blob_garbage_collection_age_cutoff`. (For example,
if the new option is set to 0.9, targeted compactions will get scheduled if the
sum of garbage bytes meets or exceeds 90% of the sum of total bytes in the
oldest blob files, assuming all affected blob files are below the age-based cutoff.)
The net result of these targeted compactions is that the valid blobs in the oldest
blob files are relocated and the oldest blob files themselves cleaned up (since
*all* SST files that rely on them get compacted away).
These targeted compactions are similar to periodic compactions in the sense
that they force certain SST files that otherwise would not get picked up to undergo
compaction and also in the sense that instead of merging files from multiple levels,
they target a single file. (Note: such compactions might still include neighboring files
from the same level due to the need of having a "clean cut" boundary but they never
include any files from any other level.)
This functionality is currently only supported with the leveled compaction style
and is inactive by default (since the default value is set to 1.0, i.e. 100%).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8994
Test Plan: Ran `make check` and tested using `db_bench` and the stress/crash tests.
Reviewed By: riversand963
Differential Revision: D31489850
Pulled By: ltamasi
fbshipit-source-id: 44057d511726a0e2a03c5d9313d7511b3f0c4eab
Summary:
This change adds File IO Notifications to the SequentialFileReader The SequentialFileReader is extended
with a listener parameter.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8982
Test Plan:
A new test EventListenerTest::OnWALOperationTest has been added. The
test verifies that during restore the sequential file reader is called
and the notifications are fired.
Reviewed By: riversand963
Differential Revision: D31320844
Pulled By: shrfb
fbshipit-source-id: 040b24da7c010d7c14ebb5c6460fae9a19b8c168
Summary:
This header file was including everything and the kitchen sink when it did not need to. This resulted in many places including this header when they needed other pieces instead.
Cleaned up this header to only include what was needed and fixed up the remaining code to include what was now missing.
Hopefully, this sort of code hygiene cleanup will speed up the builds...
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8930
Reviewed By: pdillinger
Differential Revision: D31142788
Pulled By: mrambacher
fbshipit-source-id: 6b45de3f300750c79f751f6227dece9cfd44085d
Summary:
`RandomAccessFileReader::MultiRead()` tries to merge requests in direct IO, assuming input IO requests are
sorted by offsets.
Add a test in direct IO mode.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8953
Test Plan: make check
Reviewed By: ltamasi
Differential Revision: D31183546
Pulled By: riversand963
fbshipit-source-id: 5d043ec68e2daa47a3149066150afd41ee3d73e6
Summary:
The patch adjusts the definition of BlobDB's DB properties a bit by
switching to `GetBlobFileSize` from `GetTotalBlobBytes`. The
difference is that the value returned by `GetBlobFileSize` includes
the blob file header and footer as well, and thus matches the on-disk
size of blob files. In addition, the patch removes the `Version` number
from the `blob_stats` property, and updates/extends the unit tests a little.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8902
Test Plan: `make check`
Reviewed By: riversand963
Differential Revision: D30859542
Pulled By: ltamasi
fbshipit-source-id: e3426d2d567bd1bd8c8636abdafaafa0743c854c
Summary:
RocksDB exposes certain internal statistics via the DB property interface.
However, there are currently no properties related to BlobDB.
For starters, we would like to add the following BlobDB properties:
`rocksdb.num-blob-files`: number of blob files in the current Version (kind of like `num-files-at-level` but note this is not per level, since blob files are not part of the LSM tree).
`rocksdb.blob-stats`: this could return the total number and size of all blob files, and potentially also the total amount of garbage (in bytes) in the blob files in the current Version.
`rocksdb.total-blob-file-size`: the total size of all blob files (as a blob counterpart for `total-sst-file-size`) of all Versions.
`rocksdb.live-blob-file-size`: the total size of all blob files in the current Version.
`rocksdb.estimate-live-data-size`: this is actually an existing property that we can extend so it considers blob files as well. When it comes to blobs, we actually have an exact value for live bytes. Namely, live bytes can be computed simply as total bytes minus garbage bytes, summed over the entire set of blob files in the Version.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8734
Test Plan:
```
➜ rocksdb git:(new_feature_blobDB_properties) ./db_blob_basic_test
[==========] Running 16 tests from 2 test cases.
[----------] Global test environment set-up.
[----------] 10 tests from DBBlobBasicTest
[ RUN ] DBBlobBasicTest.GetBlob
[ OK ] DBBlobBasicTest.GetBlob (12 ms)
[ RUN ] DBBlobBasicTest.MultiGetBlobs
[ OK ] DBBlobBasicTest.MultiGetBlobs (11 ms)
[ RUN ] DBBlobBasicTest.GetBlob_CorruptIndex
[ OK ] DBBlobBasicTest.GetBlob_CorruptIndex (10 ms)
[ RUN ] DBBlobBasicTest.GetBlob_InlinedTTLIndex
[ OK ] DBBlobBasicTest.GetBlob_InlinedTTLIndex (12 ms)
[ RUN ] DBBlobBasicTest.GetBlob_IndexWithInvalidFileNumber
[ OK ] DBBlobBasicTest.GetBlob_IndexWithInvalidFileNumber (9 ms)
[ RUN ] DBBlobBasicTest.GenerateIOTracing
[ OK ] DBBlobBasicTest.GenerateIOTracing (11 ms)
[ RUN ] DBBlobBasicTest.BestEffortsRecovery_MissingNewestBlobFile
[ OK ] DBBlobBasicTest.BestEffortsRecovery_MissingNewestBlobFile (13 ms)
[ RUN ] DBBlobBasicTest.GetMergeBlobWithPut
[ OK ] DBBlobBasicTest.GetMergeBlobWithPut (11 ms)
[ RUN ] DBBlobBasicTest.MultiGetMergeBlobWithPut
[ OK ] DBBlobBasicTest.MultiGetMergeBlobWithPut (14 ms)
[ RUN ] DBBlobBasicTest.BlobDBProperties
[ OK ] DBBlobBasicTest.BlobDBProperties (21 ms)
[----------] 10 tests from DBBlobBasicTest (124 ms total)
[----------] 6 tests from DBBlobBasicTest/DBBlobBasicIOErrorTest
[ RUN ] DBBlobBasicTest/DBBlobBasicIOErrorTest.GetBlob_IOError/0
[ OK ] DBBlobBasicTest/DBBlobBasicIOErrorTest.GetBlob_IOError/0 (12 ms)
[ RUN ] DBBlobBasicTest/DBBlobBasicIOErrorTest.GetBlob_IOError/1
[ OK ] DBBlobBasicTest/DBBlobBasicIOErrorTest.GetBlob_IOError/1 (10 ms)
[ RUN ] DBBlobBasicTest/DBBlobBasicIOErrorTest.MultiGetBlobs_IOError/0
[ OK ] DBBlobBasicTest/DBBlobBasicIOErrorTest.MultiGetBlobs_IOError/0 (10 ms)
[ RUN ] DBBlobBasicTest/DBBlobBasicIOErrorTest.MultiGetBlobs_IOError/1
[ OK ] DBBlobBasicTest/DBBlobBasicIOErrorTest.MultiGetBlobs_IOError/1 (10 ms)
[ RUN ] DBBlobBasicTest/DBBlobBasicIOErrorTest.CompactionFilterReadBlob_IOError/0
[ OK ] DBBlobBasicTest/DBBlobBasicIOErrorTest.CompactionFilterReadBlob_IOError/0 (1011 ms)
[ RUN ] DBBlobBasicTest/DBBlobBasicIOErrorTest.CompactionFilterReadBlob_IOError/1
[ OK ] DBBlobBasicTest/DBBlobBasicIOErrorTest.CompactionFilterReadBlob_IOError/1 (1013 ms)
[----------] 6 tests from DBBlobBasicTest/DBBlobBasicIOErrorTest (2066 ms total)
[----------] Global test environment tear-down
[==========] 16 tests from 2 test cases ran. (2190 ms total)
[ PASSED ] 16 tests.
```
Reviewed By: ltamasi
Differential Revision: D30690849
Pulled By: Zhiyi-Zhang
fbshipit-source-id: a7567319487ad76bd1a2e24bf143afdbbd9e4346
Summary:
Some FIFO users want to keep the data for longer, but the old data is rarely accessed. This feature allows users to configure FIFO compaction so that data older than a threshold is moved to a warm storage tier.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8310
Test Plan: Add several unit tests.
Reviewed By: ajkr
Differential Revision: D28493792
fbshipit-source-id: c14824ea634814dee5278b449ab5c98b6e0b5501
Summary:
The main challenge to make the memtable garbage collection prototype (nicknamed `mempurge`) was to not get rid of WAL files that contain unflushed (but mempurged) data. That was successfully guaranteed by not writing the VersionEdit to the MANIFEST file after a successful mempurge.
By not writing VersionEdits to the `MANIFEST` file after a succesful mempurge operation, we do not change the earliest log file number that contains unflushed data: `cfd->GetLogNumber()` (`cfd->SetLogNumber()` is only called in `VersionSet::ProcessManifestWrites`). As a result, a number of functions introduced earlier just for the mempurge operation are not obscolete/redundant. (e.g.: `FlushJob::ExtractEarliestLogFileNumber`), and this PR aims at cleaning up all these now-unnecessary functions. In particular, we no longer need to store the earliest log file number in the `MemTable` struct itself. This PR therefore also reverts the `MemTable` struct to its original form.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8558
Test Plan: Already included in `db_flush_test.cc`.
Reviewed By: anand1976
Differential Revision: D29764351
Pulled By: bjlemaire
fbshipit-source-id: 0f43b260fa270251862512f397d3f24ee62e8437
Summary:
If the primary's CURRENT file is missing or inaccessible, the secondary should not hang
trying repeatedly to switch to the next MANIFEST.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8200
Test Plan: make check
Reviewed By: jay-zhuang
Differential Revision: D27840627
Pulled By: riversand963
fbshipit-source-id: 071fed97cbab1bc5cdefd1dc235e5cd406c174e1
Summary:
In this PR, `mempurge` is made compatible with the Write Ahead Log: in case of recovery, the DB is now capable of recovering the data that was "mempurged" and kept in the `imm()` list of immutable memtables.
The twist was to add a uint64_t to the `memtable` struct to store the number of the earliest log file containing entries from the `memtable`. When a `Flush` operation is replaced with a `MemPurge`, the `VersionEdit` (which usually contains the new min log file number to pick up for recovery and the level 0 file path of the newly created SST file) is no longer appended to the manifest log, and every time the `deleteWal` method is called, a check is made on the list of immutable memtables.
This PR also includes a unit test that verifies that no data is lost upon Reopening of the database when the mempurge feature is activated. This extensive unit test includes two column families, with valid data contained in the imm() at time of "crash"/reopening (recovery).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8528
Reviewed By: pdillinger
Differential Revision: D29701097
Pulled By: bjlemaire
fbshipit-source-id: 072a900fb6ccc1edcf5eef6caf88f3060238edf9
Summary:
This PR is for https://github.com/facebook/rocksdb/issues/8453
We need to update `s = biter.status();` when `biter.status().IsIncomplete()` is true. By doing this, can fix the problem in issue.
Besides, we still need to update `db_statistics` in `get_context.ReportCounters()` before return back.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8485
Reviewed By: jay-zhuang
Differential Revision: D29604835
Pulled By: ajkr
fbshipit-source-id: c7f2f1cd058223ce1b507ec05d57cf264b9c9710
Summary:
Added BlobMetaData to ColumnFamilyMetaData and LiveBlobMetaData and DB API GetLiveBlobMetaData to retrieve it.
First pass at struct. More tests and maybe fields to come...
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8273
Reviewed By: ltamasi
Differential Revision: D29102400
Pulled By: mrambacher
fbshipit-source-id: 8a2383a4446328be6b91dced9841fdd3dfc80b73
Summary:
In PR https://github.com/facebook/rocksdb/issues/7523 , checksum handoff is introduced in RocksDB for WAL, Manifest, and SST files. When user enable checksum handoff for a certain type of file, before the data is written to the lower layer storage system, we calculate the checksum (crc32c) of each piece of data and pass the checksum down with the data, such that data verification can be down by the lower layer storage system if it has the capability. However, it cannot cover the whole lifetime of the data in the memory and also it potentially introduces extra checksum calculation overhead.
In this PR, we introduce a new interface in WritableFileWriter::Append, which allows the caller be able to pass the data and the checksum (crc32c) together. In this way, WritableFileWriter can directly use the pass-in checksum (crc32c) to generate the checksum of data being passed down to the storage system. It saves the calculation overhead and achieves higher protection coverage. When a new checksum is added with the data, we use Crc32cCombine https://github.com/facebook/rocksdb/issues/8305 to combine the existing checksum and the new checksum. To avoid the segmenting of data by rate-limiter before it is stored, rate-limiter is called enough times to accumulate enough credits for a certain write. This design only support Manifest and WAL which use log_writer in the current stage.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8412
Test Plan: make check, add new testing cases.
Reviewed By: anand1976
Differential Revision: D29151545
Pulled By: zhichao-cao
fbshipit-source-id: 75e2278c5126cfd58393c67b1efd18dcc7a30772
Summary:
`VersionSet::VerifyCompactionFileConsistency` was superseded by the LSM tree
consistency checks introduced in https://github.com/facebook/rocksdb/pull/6901,
which are more comprehensive, more efficient, and are performed unconditionally
even in release builds.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8449
Test Plan: `make check`
Reviewed By: ajkr
Differential Revision: D29337441
Pulled By: ltamasi
fbshipit-source-id: a05324f88e3400e27e6a00406c878a6276e0c9cc
Summary:
This reverts commit 25be1ed66a.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8438
Test Plan: Run the impacted mysql test 40 times
Reviewed By: ajkr
Differential Revision: D29286247
Pulled By: jay-zhuang
fbshipit-source-id: d3bd056971a19a8b012d5d0295fa045c012b3c04
Summary:
`DeleteFilesInRange()` marks deleting files to `being_compacted`
before deleting, which may cause ongoing compactions report corruption
exception or ASSERT for debug build.
Adding the missing `ComputeCompactionScore()` when `being_compacted` is set.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8434
Test Plan: Unittest
Reviewed By: ajkr
Differential Revision: D29276127
Pulled By: jay-zhuang
fbshipit-source-id: f5b223e3c1fc6d821e100e3f3442bc70c1d50cf7
Summary:
This is the next part of the ImmutableOptions cleanup. After changing the use of ImmutableCFOptions to ImmutableOptions, there were places in the code that had did something like "ImmutableOptions* immutable_cf_options", where "cf" referred to the "old" type.
This change simply renames the variables to match the current type. No new functionality is introduced.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8409
Reviewed By: pdillinger
Differential Revision: D29166248
Pulled By: mrambacher
fbshipit-source-id: 96de97f8e743f5c5160f02246e3ed8269556dc6f
Summary:
This reverts commit 9167ece586.
It was found to reliably trip a compaction picking conflict assertion in a MyRocks unit test. We don't understand why yet so reverting in the meantime.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8410
Test Plan: `make check -j48`
Reviewed By: jay-zhuang
Differential Revision: D29150300
Pulled By: ajkr
fbshipit-source-id: 2de8664f355d6da015e84e5fec2e3f90f49741c8
Summary:
This PR add support for Merge operation in Integrated BlobDB with base values(i.e DB::Put). Merged values can be retrieved through DB::Get, DB::MultiGet, DB::GetMergeOperands and Iterator operation.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8292
Test Plan: Add new unit tests
Reviewed By: ltamasi
Differential Revision: D28415896
Pulled By: akankshamahajan15
fbshipit-source-id: e9b3478bef51d2f214fb88c31ed3c8d2f4a531ff
Summary:
Currently, we either use the file system inode or a monotonically incrementing runtime ID as the block cache key prefix. However, if we use a monotonically incrementing runtime ID (in the case that the file system does not support inode id generation), in some cases, it cannot ensure uniqueness (e.g., we have secondary cache migrated from host to host). We use DbSessionID (20 bytes) + current file number (at most 10 bytes) as the new cache block key prefix when the secondary cache is enabled. So can accommodate scenarios such as transfer of cache state across hosts.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8360
Test Plan: add the test to lru_cache_test
Reviewed By: pdillinger
Differential Revision: D29006215
Pulled By: zhichao-cao
fbshipit-source-id: 6cff686b38d83904667a2bd39923cd030df16814
Summary:
This is a duplicate of https://github.com/facebook/rocksdb/issues/4948 by mzhaom to fix tests after rebase.
This change is a follow-up to https://github.com/facebook/rocksdb/issues/4927, which made this possible by allowing tombstone dropping/seqnum zeroing optimizations on the last key in the compaction. Now the `largest_seqno != 0` condition suffices to prevent snapshot release triggered compaction from entering an infinite loop.
The issues caused by the extraneous condition `level_and_file.second->num_deletions > 1` are:
- files could have `largest_seqno > 0` forever making it impossible to tell they cannot contain any covering keys
- it doesn't trigger compaction when there are many overwritten keys. Some MyRocks use case actually doesn't use Delete but instead calls Put with empty value to "delete" keys, so we'd like to be able to trigger compaction in this case too.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8357
Test Plan: - make check
Reviewed By: jay-zhuang
Differential Revision: D28855340
Pulled By: ajkr
fbshipit-source-id: a261b51eecafec492499e6d01e8e43112f801798
Summary:
As a part of tiered storage, writing tempeature information to manifest is needed so that after DB recovery, RocksDB still has the tiering information, to implement some further necessary functionalities.
Also fix some issues in simulated hybrid FS.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8284
Test Plan: Add a new unit test to validate that the information is indeed written and read back.
Reviewed By: zhichao-cao
Differential Revision: D28335801
fbshipit-source-id: 56aeb2e6ea090be0200181dd968c8a7278037def
Summary:
Refactor kill point to one single class, rather than several extern variables. The intention was to drop unflushed data before killing to simulate some job, and I tried to a pointer to fault ingestion fs to the killing class, but it ended up with harder than I thought. Perhaps we'll need to do this in another way. But I thought the refactoring itself is good so I send it out.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8241
Test Plan: make release and run crash test for a while.
Reviewed By: anand1976
Differential Revision: D28078486
fbshipit-source-id: f9182c1455f52e6851c13f88a21bade63bcec45f
Summary:
The ImmutableCFOptions contained a bunch of fields that belonged to the ImmutableDBOptions. This change cleans that up by introducing an ImmutableOptions struct. Following the pattern of Options struct, this class inherits from the DB and CFOption structs (of the Immutable form).
Only one structural change (the ImmutableCFOptions::fs was changed to a shared_ptr from a raw one) is in this PR. All of the other changes involve moving the member variables from the ImmutableCFOptions into the ImmutableOptions and changing member variables or function parameters as required for compilation purposes.
Follow-on PRs may do a further clean-up of the code, such as renaming variables (such as "ImmutableOptions cf_options") and potentially eliminating un-needed function parameters (there is no longer a need to pass both an ImmutableDBOptions and an ImmutableOptions to a function).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8262
Reviewed By: pdillinger
Differential Revision: D28226540
Pulled By: mrambacher
fbshipit-source-id: 18ae71eadc879dedbe38b1eb8e6f9ff5c7147dbf
Summary:
Renaming ImmutableCFOptions::info_log and statistics to logger and stats. This is stage 2 in creating an ImmutableOptions class. It is necessary because the names match those in ImmutableOptions and have different types.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8227
Reviewed By: jay-zhuang
Differential Revision: D28000967
Pulled By: mrambacher
fbshipit-source-id: 3bf2aa04e8f1e8724d825b7deacf41080c14420b
Summary:
This PR is a first step at attempting to clean up some of the Mutable/Immutable Options code. With this change, a DBOption and a ColumnFamilyOption can be reconstructed from their Mutable and Immutable equivalents, respectively.
readrandom tests do not show any performance degradation versus master (though both are slightly slower than the current 6.19 release).
There are still fields in the ImmutableCFOptions that are not CF options but DB options. Eventually, I would like to move those into an ImmutableOptions (= ImmutableDBOptions+ImmutableCFOptions). But that will be part of a future PR to minimize changes and disruptions.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8176
Reviewed By: pdillinger
Differential Revision: D27954339
Pulled By: mrambacher
fbshipit-source-id: ec6b805ba9afe6e094bffdbd76246c2d99aa9fad
Summary:
In a distributed environment, a file `rename()` operation can succeed on server (remote)
side, but the client can somehow return non-ok status to RocksDB. Possible reasons include
network partition, connection issue, etc. This happens in `rocksdb::SetCurrentFile()`, which
can be called in `LogAndApply() -> ProcessManifestWrites()` if RocksDB tries to switch to a
new MANIFEST. We currently always delete the new MANIFEST if an error occurs.
This is problematic in distributed world. If the server-side successfully updates the CURRENT
file via renaming, then a subsequent `DB::Open()` will try to look for the new MANIFEST and fail.
As a fix, we can track the execution result of IO operations on the new MANIFEST.
- If IO operations on the new MANIFEST fail, then we know the CURRENT must point to the original
MANIFEST. Therefore, it is safe to remove the new MANIFEST.
- If IO operations on the new MANIFEST all succeed, but somehow we end up in the clean up
code block, then we do not know whether CURRENT points to the new or old MANIFEST. (For local
POSIX-compliant FS, it should still point to old MANIFEST, but it does not matter if we keep the
new MANIFEST.) Therefore, we keep the new MANIFEST.
- Any future `LogAndApply()` will switch to a new MANIFEST and update CURRENT.
- If process reopens the db immediately after the failure, then the CURRENT file can point
to either the new MANIFEST or the old one, both of which exist. Therefore, recovery can
succeed and ignore the other.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8192
Test Plan: make check
Reviewed By: zhichao-cao
Differential Revision: D27804648
Pulled By: riversand963
fbshipit-source-id: 9c16f2a5ce41bc6aadf085e48449b19ede8423e4
Summary:
If `options.best_efforts_recovery == true`, RocksDB currently tolerates missing table files and recovers to the latest version without missing table files (not considering WAL). It is necessary to handle blob files as well to make the feature more complete.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8180
Test Plan: make check
Reviewed By: ltamasi
Differential Revision: D27840556
Pulled By: riversand963
fbshipit-source-id: 041685d0dc2e7779ac4f0374c07a8a327704aa5e
Summary:
Extend the DB::GetLiveFilesChecksumInfo API to blob files.
This API is also used by the file_checksum_dump ldb command to dump checksum
of SST files which now also dumps blob files checksum.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8179
Test Plan: Add new unit test
Reviewed By: zhichao-cao
Differential Revision: D27714965
Pulled By: akankshamahajan15
fbshipit-source-id: d8b7343ea845a64c83800336d88cced7152a8c92
Summary:
**Summary:**
When doing CompactFiles on the files of multiple levels(num_level > 2) with L0 is included, the compaction would fail like this.
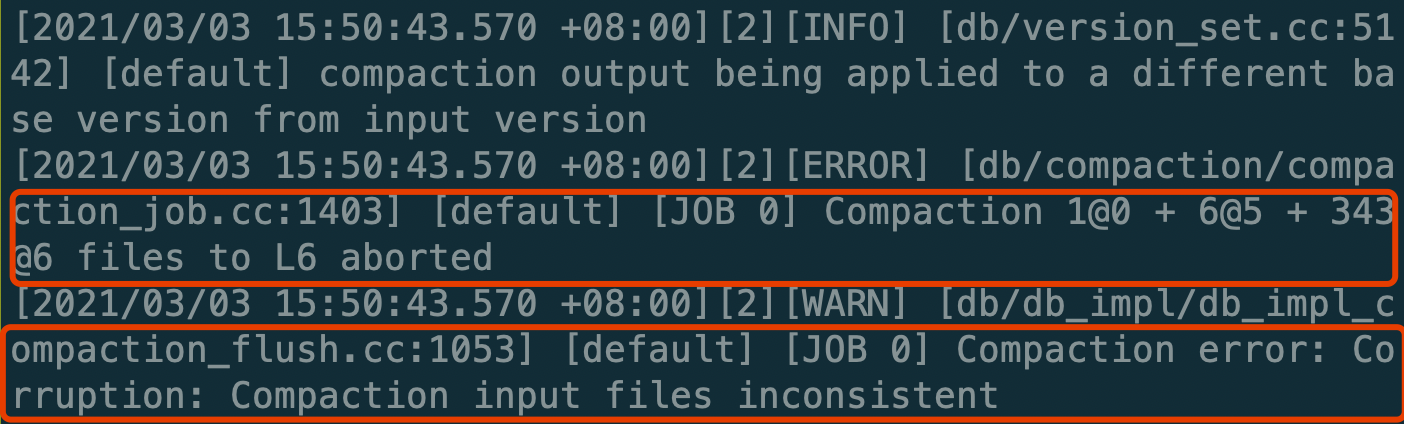
The reason is that in `VerifyCompactionFileConsistency` it checks the levels between the L0 and base level should be empty, but it regards the compaction triggered by `CompactFiles` as an L0 -> base level compaction wrongly.
The condition is committed several years ago, whereas it isn't correct anymore.
```c++
if (vstorage->compaction_style_ == kCompactionStyleLevel &&
c->start_level() == 0 && c->num_input_levels() > 2U)
```
So this PR just deletes the incorrect check.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8024
Test Plan: make check
Reviewed By: jay-zhuang
Differential Revision: D26907060
Pulled By: ajkr
fbshipit-source-id: 538cef32faf464cd422e3f8de236ea3e58880c2b
Summary:
For performance purposes, the lower level routines were changed to use a SystemClock* instead of a std::shared_ptr<SystemClock>. The shared ptr has some performance degradation on certain hardware classes.
For most of the system, there is no risk of the pointer being deleted/invalid because the shared_ptr will be stored elsewhere. For example, the ImmutableDBOptions stores the Env which has a std::shared_ptr<SystemClock> in it. The SystemClock* within the ImmutableDBOptions is essentially a "short cut" to gain access to this constant resource.
There were a few classes (PeriodicWorkScheduler?) where the "short cut" property did not hold. In those cases, the shared pointer was preserved.
Using db_bench readrandom perf_level=3 on my EC2 box, this change performed as well or better than 6.17:
6.17: readrandom : 28.046 micros/op 854902 ops/sec; 61.3 MB/s (355999 of 355999 found)
6.18: readrandom : 32.615 micros/op 735306 ops/sec; 52.7 MB/s (290999 of 290999 found)
PR: readrandom : 27.500 micros/op 871909 ops/sec; 62.5 MB/s (367999 of 367999 found)
(Note that the times for 6.18 are prior to revert of the SystemClock).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8033
Reviewed By: pdillinger
Differential Revision: D27014563
Pulled By: mrambacher
fbshipit-source-id: ad0459eba03182e454391b5926bf5cdd45657b67
Summary:
This PR
- adds a class `ManifestTailer` that inherits from `VersionEditHandlerPointInTime`. `ManifestTailer::Iterate()` can be called multiple times to tail the primary instance's MANIFEST and apply the changes to the secondary,
- updates the implementation of `ReactiveVersionSet::ReadAndApply` to use this class,
- removes unused code in version_set.cc,
- updates existing tests, e.g. removing deleted sync points from unit tests,
- adds a new test to address the bug in https://github.com/facebook/rocksdb/issues/7815.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7998
Test Plan:
make check
Existing and newly-added tests in version_set_test.cc and db_secondary_test.cc
Reviewed By: jay-zhuang
Differential Revision: D26926641
Pulled By: riversand963
fbshipit-source-id: 8d4dd15db0ba863c213f743e33b5a207e948c980
{kind=link}