Summary:
Return early in case there are zero data blocks when
`BlockBasedTableBuilder::EnterUnbuffered()` is called. This crash can
only be triggered by applying dictionary compression to SST files that
contain only range tombstones. It cannot be triggered by a low buffer
limit alone since we only consider entering unbuffered mode after
buffering a data block causing the limit to be breached, or `Finish()`ing the file. It also cannot
be triggered by a totally empty file because those go through
`Abandon()` rather than `Finish()` so unbuffered mode is never entered.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8141
Test Plan: added a unit test that repro'd the "Floating point exception"
Reviewed By: riversand963
Differential Revision: D27495640
Pulled By: ajkr
fbshipit-source-id: a463cfba476919dc5c5c380800a75a86c31ffa23
Summary:
Added `TableProperties::{fast,slow}_compression_estimated_data_size`.
These properties are present in block-based tables when
`ColumnFamilyOptions::sample_for_compression > 0` and the necessary
compression library is supported when the file is generated. They
contain estimates of what `TableProperties::data_size` would be if the
"fast"/"slow" compression library had been used instead. One
limitation is we do not record exactly which "fast" (ZSTD or Zlib)
or "slow" (LZ4 or Snappy) compression library produced the result.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8139
Test Plan:
- new unit test
- ran `db_bench` with `sample_for_compression=1`; verified the `data_size` property matches the `{slow,fast}_compression_estimated_data_size` when the same compression type is used for the output file compression and the sampled compression
Reviewed By: riversand963
Differential Revision: D27454338
Pulled By: ajkr
fbshipit-source-id: 9529293de93ddac7f03b2e149d746e9f634abac4
Summary:
Fix error_handler_fs_test failure due to statistics, it will fails due to multi-thread running and resume is different.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8136
Test Plan: make check
Reviewed By: akankshamahajan15
Differential Revision: D27448828
Pulled By: zhichao-cao
fbshipit-source-id: b94255c45e9e66e93334b5ca2e4e1bfcba23fc20
Summary:
In DBImpl::CloseHelper, we wait for bg_compaction_scheduled_
and bg_flush_scheduled_ to drop to 0. Unschedule is called prior
to cancel any unscheduled flushes/compactions. It is assumed that
anything in the high priority is a flush, and anything in the low
priority pool is a compaction. This assumption, however, is broken when
the high-pri pool is full.
As a result, bg_compaction_scheduled_ can go < 0 and bg_flush_scheduled_
will remain > 0 and DB can be in hang state.
The fix is, we decrement the `bg_{flush,compaction,bottom_compaction}_scheduled_`
inside the `Unschedule{Flush,Compaction,BottomCompaction}Callback()`s. DB
`mutex_` will make the counts atomic in `Unschedule`.
Related discussion: https://github.com/facebook/rocksdb/issues/7928
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8125
Test Plan: Added new test case which hangs without the fix.
Reviewed By: jay-zhuang
Differential Revision: D27390043
Pulled By: ajkr
fbshipit-source-id: 78a367fba9a59ac5607ad24bd1c46dc16d5ec110
Summary:
Currently, we only truncate the latest alive WAL files when the DB is opened. If the latest WAL file is empty or was flushed during Open, its not truncated since the file will be deleted later on in the Open path. However, before deletion, a new WAL file is created, and if the process crash loops between the new WAL file creation and deletion of the old WAL file, the preallocated space will keep accumulating and eventually use up all disk space. To prevent this, always truncate the latest WAL file, even if its empty or the data was flushed.
Tests:
Add unit tests to db_wal_test
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8122
Reviewed By: riversand963
Differential Revision: D27366132
Pulled By: anand1976
fbshipit-source-id: f923cc03ef033ccb32b140d36c6a63a8152f0e8e
Summary:
The snapshot structure returned by rocksdb_transaction_get_snapshot is
supposed to be freed by calling rocksdb_free(), so allocate using malloc
rather than new. Fixes https://github.com/facebook/rocksdb/issues/6112
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8114
Reviewed By: akankshamahajan15
Differential Revision: D27362923
Pulled By: anand1976
fbshipit-source-id: e93a8b1ffe26dafbe22529907f72b796ae971214
Summary:
The patch adds a resource management/RAII class called `ThreadGuard`,
which can be used to ensure that the managed thread is joined when the
`ThreadGuard` is destroyed, regardless of whether it is due to the
object going out of scope, an early return, an exception etc. This is
important because if an `std::thread` object is destroyed without having
been joined (or detached) first, the process is aborted (via
`std::terminate`).
For now, `ThreadGuard` is only used in the test case
`ExternalSSTFileTest.PickedLevelBug`; however, it could come in handy
elsewhere in the codebase as well (both in test code and "real" code).
Case in point: in the `PickedLevelBug` test case, with the earlier code we
could end up in the above situation when the following assertion (which is
before the threads are joined) is triggered:
```
ASSERT_FALSE(bg_compact_started.load());
```
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8112
Test Plan:
```
make check
gtest-parallel --repeat=10000 ./external_sst_file_test --gtest_filter="*PickedLevelBug"
```
Reviewed By: riversand963
Differential Revision: D27343185
Pulled By: ltamasi
fbshipit-source-id: 2a8c3aa68bc78cc03ec0dbae909fb25c2cd15c69
Summary:
There is bug in the current code base introduced in https://github.com/facebook/rocksdb/issues/8049 , we still set the SST file write IO Error only case as hard error. Fix it by removing the logic.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8107
Test Plan: make check, error_handler_fs_test
Reviewed By: anand1976
Differential Revision: D27321422
Pulled By: zhichao-cao
fbshipit-source-id: c014afc1553ca66b655e3bbf9d0bf6eb417ccf94
Summary:
Previously it only applied to block-based tables generated by flush. This restriction
was undocumented and blocked a new use case. Now compression sampling
applies to all block-based tables we generate when it is enabled.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8105
Test Plan: new unit test
Reviewed By: riversand963
Differential Revision: D27317275
Pulled By: ajkr
fbshipit-source-id: cd9fcc5178d6515e8cb59c6facb5ac01893cb5b0
Summary:
`strerror()` is not thread-safe, using `strerror_r()` instead. The API could be different on the different platforms, used the code from 0deef031cb/folly/String.cpp (L457)
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8087
Reviewed By: mrambacher
Differential Revision: D27267151
Pulled By: jay-zhuang
fbshipit-source-id: 4b8856d1ec069d5f239b764750682c56e5be9ddb
Summary:
**Summary:**
When doing CompactFiles on the files of multiple levels(num_level > 2) with L0 is included, the compaction would fail like this.
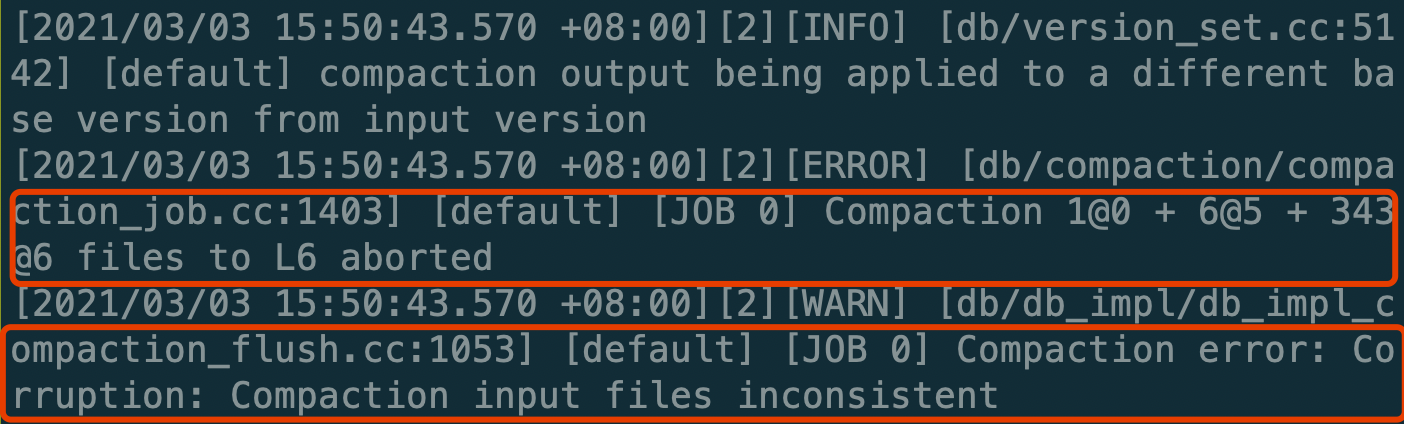
The reason is that in `VerifyCompactionFileConsistency` it checks the levels between the L0 and base level should be empty, but it regards the compaction triggered by `CompactFiles` as an L0 -> base level compaction wrongly.
The condition is committed several years ago, whereas it isn't correct anymore.
```c++
if (vstorage->compaction_style_ == kCompactionStyleLevel &&
c->start_level() == 0 && c->num_input_levels() > 2U)
```
So this PR just deletes the incorrect check.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8024
Test Plan: make check
Reviewed By: jay-zhuang
Differential Revision: D26907060
Pulled By: ajkr
fbshipit-source-id: 538cef32faf464cd422e3f8de236ea3e58880c2b
Summary:
Fix race condition in
DBSSTTest.DBWithMaxSpaceAllowedWithBlobFiles where background flush
thread updates delete_blob_file but in test thread Flush() already
completes after getting bg_error and delete_blob_file remains false.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8092
Test Plan: Ran ASAN job few times on CircleCI
Reviewed By: riversand963
Differential Revision: D27275815
Pulled By: akankshamahajan15
fbshipit-source-id: 2939ad1671403881573bbe07c71aa474c5019130
Summary:
As title. All core db implementations should stay in db_impl.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8082
Test Plan: make check
Reviewed By: ajkr
Differential Revision: D27211442
Pulled By: riversand963
fbshipit-source-id: e0953fde75064740e899aaff7989ff033b7f5232
Summary:
Add the new Append and PositionedAppend API to env WritableFile. User is able to benefit from the write checksum handoff API when using the legacy Env classes. FileSystem already implemented the checksum handoff API.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8071
Test Plan: make check, added new unit test.
Reviewed By: anand1976
Differential Revision: D27177043
Pulled By: zhichao-cao
fbshipit-source-id: 430c8331fc81099fa6d00f4fff703b68b9e8080e
Summary:
In previous codebase, if WAL is used, all the retryable IO Error will be treated as hard error. So write is stalled. In this PR, the retryable IO error from WAL sync is separated from SST file flush io error. If WAL Sync is ok and retryable IO Error only happens during SST flush, the error is mapped to soft error. So user can continue insert to Memtable and append to WAL.
Resolve the bug that if WAL sync fails, the memtable status does not roll back due to calling PickMemtable early than calling and checking SyncClosedLog.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8049
Test Plan: added new unit test, make check
Reviewed By: anand1976
Differential Revision: D26965529
Pulled By: zhichao-cao
fbshipit-source-id: f5fecb66602212523c92ee49d7edcb6065982410
Summary:
WriteController had a number of issues:
* It could introduce a delay of 1ms even if the write rate never exceeded the
configured delayed_write_rate.
* The DB-wide delayed_write_rate could be exceeded in a number of ways
with multiple column families:
* Wiping all pending delay "debts" when another column family joins
the delay with GetDelayToken().
* Resetting last_refill_time_ to (now + sleep amount) means each
column family can write with delayed_write_rate for large writes.
* Updating bytes_left_ for a partial refill without updating
last_refill_time_ would essentially give out random bonuses,
especially to medium-sized writes.
Now the code is much simpler, with these issues fixed. See comments in
the new code and new (replacement) tests.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8064
Test Plan: new tests, better than old tests
Reviewed By: mrambacher
Differential Revision: D27064936
Pulled By: pdillinger
fbshipit-source-id: 497c23fe6819340b8f3d440bd634d8a2bc47323f
Summary:
Add statistics and info log for error handler: counters for bg error, bg io error, bg retryable io error, auto resume, auto resume total retry, and auto resume sucess; Histogram for auto resume retry count in each recovery call.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8050
Test Plan: make check and add test to error_handler_fs_test
Reviewed By: anand1976
Differential Revision: D26990565
Pulled By: zhichao-cao
fbshipit-source-id: 49f71e8ea4e9db8b189943976404205b56ab883f
Summary:
Extend support to track blob files in SST File manager.
This PR notifies SstFileManager whenever a new blob file is created,
via OnAddFile and an obsolete blob file deleted via OnDeleteFile
and delete file via ScheduleFileDeletion.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8037
Test Plan: Add new unit tests
Reviewed By: ltamasi
Differential Revision: D26891237
Pulled By: akankshamahajan15
fbshipit-source-id: 04c69ccfda2a73782fd5c51982dae58dd11979b6
Summary:
When timestamp is enabled, key comparison should take this into account.
In `BlockBasedTableReader::Get()`, `BlockBasedTableReader::MultiGet()`,
assume the target key is `key`, and the timestamp upper bound is `ts`.
The highest key in current block is (key, ts1), while the lowest key in next
block is (key, ts2).
If
```
ts1 > ts > ts2
```
then
```
(key, ts1) < (key, ts) < (key, ts2)
```
It can be shown that if `Compare()` is used, then we will mistakenly skip the next
block. Instead, we should use `CompareWithoutTimestamp()`.
The majority of this PR makes some existing tests in `db_with_timestamp_basic_test.cc`
parameterized so that different index types can be tested. A new unit test is
also added for more coverage.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8062
Test Plan: make check
Reviewed By: ltamasi
Differential Revision: D27057557
Pulled By: riversand963
fbshipit-source-id: c1062fa7c159ed600a1ad7e461531d52265021f1
Summary:
For performance purposes, the lower level routines were changed to use a SystemClock* instead of a std::shared_ptr<SystemClock>. The shared ptr has some performance degradation on certain hardware classes.
For most of the system, there is no risk of the pointer being deleted/invalid because the shared_ptr will be stored elsewhere. For example, the ImmutableDBOptions stores the Env which has a std::shared_ptr<SystemClock> in it. The SystemClock* within the ImmutableDBOptions is essentially a "short cut" to gain access to this constant resource.
There were a few classes (PeriodicWorkScheduler?) where the "short cut" property did not hold. In those cases, the shared pointer was preserved.
Using db_bench readrandom perf_level=3 on my EC2 box, this change performed as well or better than 6.17:
6.17: readrandom : 28.046 micros/op 854902 ops/sec; 61.3 MB/s (355999 of 355999 found)
6.18: readrandom : 32.615 micros/op 735306 ops/sec; 52.7 MB/s (290999 of 290999 found)
PR: readrandom : 27.500 micros/op 871909 ops/sec; 62.5 MB/s (367999 of 367999 found)
(Note that the times for 6.18 are prior to revert of the SystemClock).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8033
Reviewed By: pdillinger
Differential Revision: D27014563
Pulled By: mrambacher
fbshipit-source-id: ad0459eba03182e454391b5926bf5cdd45657b67
Summary:
CompactionDeletionTriggerReopen was observed to be flaky recently:
https://app.circleci.com/pipelines/github/facebook/rocksdb/6030/workflows/787af4f3-b9f7-4645-8e8d-1fb0ebf05539/jobs/101451.
I went through it and the related tests and arrived at different
conclusions on what constraints we can expect on DB size. Some
constraints got looser and some got tighter. The particular constraint
that flaked got a lot looser so at least the flake linked above would have been prevented.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8036
Reviewed By: riversand963
Differential Revision: D26862566
Pulled By: ajkr
fbshipit-source-id: 3512b86b4fb41aeecae32e1c7382c03916d88d88
Summary:
`DBTest.GetLiveBlobFiles` and `ObsoleteFilesTest.BlobFiles` both modify the
current `Version` in their setup phase, implicitly assuming that no other
threads would touch the `Version` while this is happening. The periodic
stats dumper thread violates this assumption; the patch fixes this by
disabling it in the affected test cases. (Note: the data race is
harmless in the sense that it only affects test code.)
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8055
Test Plan:
```
COMPILE_WITH_TSAN=1 make db_test -j24
gtest-parallel --repeat=10000 ./db_test --gtest_filter="*GetLiveBlobFiles"
COMPILE_WITH_TSAN=1 make obsolete_files_test -j24
gtest-parallel --repeat=10000 ./obsolete_files_test --gtest_filter="*BlobFiles"
```
Reviewed By: riversand963
Differential Revision: D27022715
Pulled By: ltamasi
fbshipit-source-id: b6cc77ed63d8bc1cbe0603522ff1a572182fc9ab
Summary:
a trial gtest upgrade discovered some parameterized tests missing instantiation. By some miracle, they still pass.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8051
Test Plan: thisisthetest
Reviewed By: mrambacher
Differential Revision: D27003684
Pulled By: pdillinger
fbshipit-source-id: cde1cab1551fb282f67d462d46574bd30bd5e61f
Summary:
This PR
- adds a class `ManifestTailer` that inherits from `VersionEditHandlerPointInTime`. `ManifestTailer::Iterate()` can be called multiple times to tail the primary instance's MANIFEST and apply the changes to the secondary,
- updates the implementation of `ReactiveVersionSet::ReadAndApply` to use this class,
- removes unused code in version_set.cc,
- updates existing tests, e.g. removing deleted sync points from unit tests,
- adds a new test to address the bug in https://github.com/facebook/rocksdb/issues/7815.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7998
Test Plan:
make check
Existing and newly-added tests in version_set_test.cc and db_secondary_test.cc
Reviewed By: jay-zhuang
Differential Revision: D26926641
Pulled By: riversand963
fbshipit-source-id: 8d4dd15db0ba863c213f743e33b5a207e948c980
Summary:
Haven't seen any production issues with new Bloom filter and
it's now > 1 year old (added in 6.6.0).
Updated check_format_compatible.sh and HISTORY.md
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8017
Test Plan: tests updated (or prior bugs fixed)
Reviewed By: ajkr
Differential Revision: D26762197
Pulled By: pdillinger
fbshipit-source-id: 0e755c46b443087c1544da0fd545beb9c403d1c2
Summary:
## 1. Bug description:
When RocksDB Checkpoint, it may be stuck in `WaitUntilFlushWouldNotStallWrites` method.
## 2. Simple analysis of the reasons:
### 2.1 Configuration parameters:
```yaml
Compaction Style : Universal
max_write_buffer_number : 4
min_write_buffer_number_to_merge : 3
```
Checkpoint is usually very fast. When the Checkpoint is executed, `WaitUntilFlushWouldNotStallWrites` is called. If there are 2 Immutable MemTables, which are less than `min_write_buffer_number_to_merge`, they will not be flushed. But will enter this code.
```c++
// method: GetWriteStallConditionAndCause
if (mutable_cf_options.max_write_buffer_number> 3 &&
num_unflushed_memtables >=
mutable_cf_options.max_write_buffer_number-1) {
return {WriteStallCondition::kDelayed, WriteStallCause::kMemtableLimit};
}
```
code link: fbed72f03c/db/column_family.cc (L847)
Checkpoint thought there was a FlushJob, but it didn't. So will always wait.
### 2.2 solution:
Increase the restriction: the `number of Immutable MemTable` >= `min_write_buffer_number_to_merge will wait`.
If there are other better solutions, you can correct me.
### 2.3 Code that can reproduce the problem:
https://github.com/1996fanrui/fanrui-learning/blob/flink-1.12/module-java/src/main/java/com/dream/rocksdb/RocksDBCheckpointStuck.java
## 3. Interesting point
This bug will be triggered only when `the number of sorted runs >= level0_file_num_compaction_trigger`.
Because there is a break in WaitUntilFlushWouldNotStallWrites.
```c++
if (cfd->imm()->NumNotFlushed() <
cfd->ioptions()->min_write_buffer_number_to_merge &&
vstorage->l0_delay_trigger_count() <
mutable_cf_options.level0_file_num_compaction_trigger) {
break;
}
```
code link: fbed72f03c/db/db_impl/db_impl_compaction_flush.cc (L1974)
Universal may have `l0_delay_trigger_count() >= level0_file_num_compaction_trigger`, so this bug is triggered.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7921
Reviewed By: jay-zhuang
Differential Revision: D26900559
Pulled By: ajkr
fbshipit-source-id: 133c1252dad7393753f04a47590b68c7d8e670df
Summary:
For some reason I still cannot figure out, the manual flush in this test
was sometimes producing a third tiny file. I saw it a bunch of times on
ppc64le, but even running a qemu system with that architecture (and
playing with various other options) could not repro. However we did get
an instrumented Travis run to confirm the problem is indeed a third tiny
file - https://travis-ci.org/github/facebook/rocksdb/jobs/761986592. We
can avoid it by filling memtables less full and using manual flush.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8044
Reviewed By: akankshamahajan15
Differential Revision: D26892635
Pulled By: ajkr
fbshipit-source-id: 775c04176931cf01d07cc78fb82cfe3a11beebcf
Summary:
The patch does the following:
1) Exposes the amount of data (number of bytes) read from blob files from
`BlobFileReader::GetBlob` / `Version::GetBlob`.
2) Tracks the total number and size of blobs read from blob files during a
compaction (due to garbage collection or compaction filter usage) in
`CompactionIterationStats` and propagates this data to
`InternalStats::CompactionStats` / `CompactionJobStats`.
3) Updates the formulae for write amplification calculations to include the
amount of data read from blob files.
4) Extends the compaction stats dump with a new column `Rblob(GB)` and
a new line containing the total number and size of blob files in the current
`Version` to complement the information about the shape and size of the LSM tree
that's already there.
5) Updates `CompactionJobStats` so that the number of files and amount of data
written by a compaction are broken down per file type (i.e. table/blob file).
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8022
Test Plan: Ran `make check` and `db_bench`.
Reviewed By: riversand963
Differential Revision: D26801199
Pulled By: ltamasi
fbshipit-source-id: 28a5f072048a702643b28cb5971b4099acabbfb2
Summary:
When changing db iterator direction, we may perform a reseek.
Therefore, we should bump the NUMBER_OF_RESEEKS_IN_ITERATION counter.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8015
Test Plan: make check
Reviewed By: ltamasi
Differential Revision: D26755415
Pulled By: riversand963
fbshipit-source-id: 211f51f1a454bcda768fc46c0dce51edeb7f05fe
Summary:
The patch breaks down the "bytes written" (as well as the "number of output files")
compaction statistics into two, so the values are logged separately for table files
and blob files in the info log, and are shown in separate columns (`Write(GB)` for table
files, `Wblob(GB)` for blob files) when the compaction statistics are dumped.
This will also come in handy for fixing the write amplification statistics, which currently
do not consider the amount of data read from blob files during compaction. (This will
be fixed by an upcoming patch.)
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8013
Test Plan: Ran `make check` and `db_bench`.
Reviewed By: riversand963
Differential Revision: D26742156
Pulled By: ltamasi
fbshipit-source-id: 31d18ee8f90438b438ca7ed1ea8cbd92114442d5
Summary:
The checkpointing logic supports passing file level checksums
to the copy_file_cb callback function which is used by the backup code
for detecting corruption during file copies.
However, this is currently implemented only for table files.
This PR extends the checksum retrieval to blob files as well.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/8003
Test Plan: Add new test units
Reviewed By: ltamasi
Differential Revision: D26680701
Pulled By: akankshamahajan15
fbshipit-source-id: 1bd1e2464df6e9aa31091d35b8c72786d94cd1c5
Summary:
Allow applications to implement a custom compaction filter and pass it to BlobDB.
The compaction filter's custom logic can operate on blobs.
To do so, application needs to subclass `CompactionFilter` abstract class and implement `FilterV2()` method.
Optionally, a method called `ShouldFilterBlobByKey()` can be implemented if application's custom logic rely solely
on the key to make a decision without reading the blob, thus saving extra IO. Examples can be found in
db/blob/db_blob_compaction_test.cc.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7974
Test Plan: make check
Reviewed By: ltamasi
Differential Revision: D26509280
Pulled By: riversand963
fbshipit-source-id: 59f9ae5614c4359de32f4f2b16684193cc537b39
Summary:
Fixed 5 test case failures found on Windows 10/Windows Server 2016
1. In `flush_job_test`, the DestroyDir function fails in deconstructor because some file handles are still being held by VersionSet. This happens on Windows Server 2016, so need to manually reset versions_ pointer to release all file handles.
2. In `StatsHistoryTest.InMemoryStatsHistoryPurging` test, the capping memory cost of stats_history_size on Windows becomes 14000 bytes with latest changes, not just 13000 bytes.
3. In `SSTDumpToolTest.RawOutput` test, the output file handle is not closed at the end.
4. In `FullBloomTest.OptimizeForMemory` test, ROCKSDB_MALLOC_USABLE_SIZE is undefined on windows so `total_mem` is always equal to `total_size`. The internal memory fragmentation assertion does not apply in this case.
5. In `BlockFetcherTest.FetchAndUncompressCompressedDataBlock` test, XPRESS cannot reach 87.5% compression ratio with original CreateTable method, so I append extra zeros to the string value to enhance compression ratio. Beside, since XPRESS allocates memory internally, thus does not support for custom allocator verification, we will skip the allocator verification for XPRESS
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7992
Reviewed By: jay-zhuang
Differential Revision: D26615283
Pulled By: ajkr
fbshipit-source-id: 3632612f84b99e2b9c77c403b112b6bedf3b125d
Summary:
Extend VerifyFileChecksums API to verify blob files in case of
use_file_checksum.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7979
Test Plan: New unit test db_blob_corruption_test
Reviewed By: ltamasi
Differential Revision: D26534040
Pulled By: akankshamahajan15
fbshipit-source-id: 7dc5951a3df9d265ea1265e0122b43c966856ade
Summary:
For dictionary compression, we need to collect some representative samples of the data to be compressed, which we use to either generate or train (when `CompressionOptions::zstd_max_train_bytes > 0`) a dictionary. Previously, the strategy was to buffer all the data blocks during flush, and up to the target file size during compaction. That strategy allowed us to randomly pick samples from as wide a range as possible that'd be guaranteed to land in a single output file.
However, some users try to make huge files in memory-constrained environments, where this strategy can cause OOM. This PR introduces an option, `CompressionOptions::max_dict_buffer_bytes`, that limits how much data blocks are buffered before we switch to unbuffered mode (which means creating the per-SST dictionary, writing out the buffered data, and compressing/writing new blocks as soon as they are built). It is not strict as we currently buffer more than just data blocks -- also keys are buffered. But it does make a step towards giving users predictable memory usage.
Related changes include:
- Changed sampling for dictionary compression to select unique data blocks when there is limited availability of data blocks
- Made use of `BlockBuilder::SwapAndReset()` to save an allocation+memcpy when buffering data blocks for building a dictionary
- Changed `ParseBoolean()` to accept an input containing characters after the boolean. This is necessary since, with this PR, a value for `CompressionOptions::enabled` is no longer necessarily the final component in the `CompressionOptions` string.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7970
Test Plan:
- updated `CompressionOptions` unit tests to verify limit is respected (to the extent expected in the current implementation) in various scenarios of flush/compaction to bottommost/non-bottommost level
- looked at jemalloc heap profiles right before and after switching to unbuffered mode during flush/compaction. Verified memory usage in buffering is proportional to the limit set.
Reviewed By: pdillinger
Differential Revision: D26467994
Pulled By: ajkr
fbshipit-source-id: 3da4ef9fba59974e4ef40e40c01611002c861465
Summary:
Added a "only_mutable_options" flag to the ConfigOptions. When set, the Configurable methods will only look at/update options that are marked as kMutable.
Fixed DB::SetOptions to allow for the update of any mutable TableFactory options. Fixes https://github.com/facebook/rocksdb/issues/7385.
Added tests for the new flag. Updated HISTORY.md
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7936
Reviewed By: akankshamahajan15
Differential Revision: D26389646
Pulled By: mrambacher
fbshipit-source-id: 6dc247f6e999fa2814059ebbd0af8face109fea0
Summary:
The trace file record and payload encode is fixed, which requires complex backward compatibility resolving. This PR introduce a new trace file format, which makes it easier to add new entries to the payload and does not have backward compatible issues. V 0.1 is still supported in this PR. Added the tracing for lower_bound and upper_bound for iterator.
Pull Request resolved: https://github.com/facebook/rocksdb/pull/7977
Test Plan: make check. tested with old trace file in replay and analyzing.
Reviewed By: anand1976
Differential Revision: D26529948
Pulled By: zhichao-cao
fbshipit-source-id: ebb75a127ce3c07c25a1ccc194c551f917896a76
{kind=link}